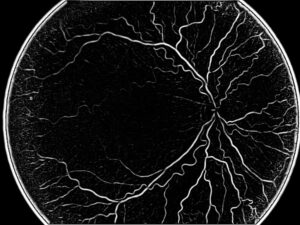
OCT images are frequently used to demonstrate the retina and understand the different pathologies and decide the diagnostics and help with procedure planning.
In medical imaging, especially in radiology, deep learning has been used in recent years to gain super-resolution. On one hand, it is possible to scan faster and more efficiently at lower resolutions. On the other hand, quality scans provide added benefits. Super-resolution is a class of techniques in image processing that enhance the resolution of an imaging system, making images sharper and clearer. By improving the quality of OCT images, super-resolution can potentially enhance our ability to detect and analyze pathological changes, thus facilitating more accurate and early diagnosis of various eye conditions.
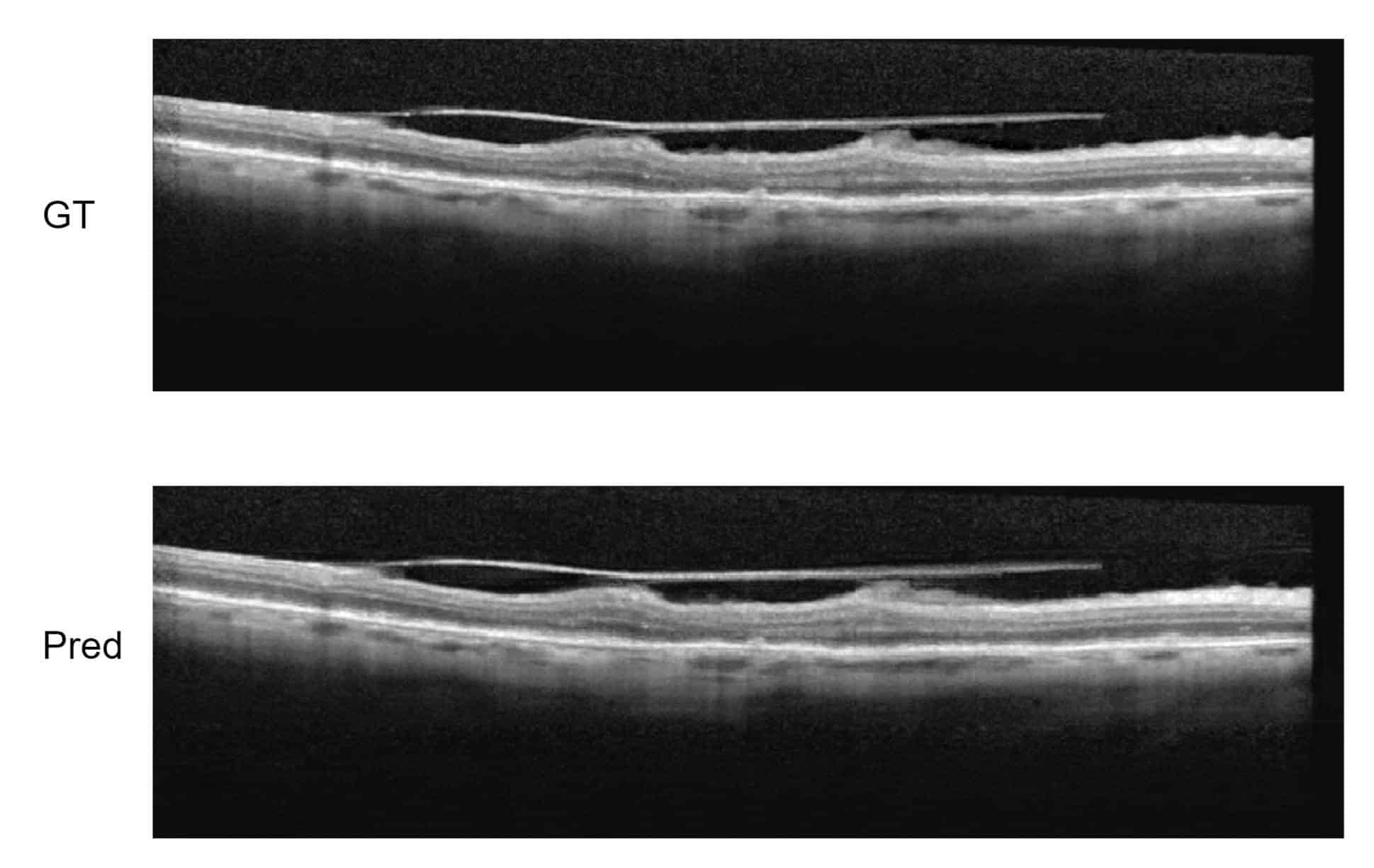
This is why we use super-resolution also in OCT images and get better resolution or – alternatively – gain scanning speed to produce images with the quality needed for the diagnostics. RSIP Vision has already done that: developing super-resolution for OCT images. It can also be useful in real-time scans, when high quality images are needed in real-time.
Several steps are indicated for the typical process, as follows.
It is crucial to select a training dataset which includes distinctive pathologies in the right proportion. Otherwise, the algorithm might be trained only for healthy eyes and would offer no clinical value. Each pathology needs to be represented in the dataset, and this for several reasons: first, to train the system also on that pathology; also, to declare to the regulatory authorities that the new algorithm won’t miss any meaningful diagnostics. From the point of view of the compliance officer – he needs to assure that no pathology is missed due to the process. The way to do it is to run on a list of typical pathologies and validate it one by one.
The training itself of the convolutional neural network will take advantage of several architectures for improving the resolution: in particular, Super-resolution CNN (SR-CNN): a model is trained on patches of OCT scan at low resolution, where higher resolution scan is known. In this manner, we go from small patches to more detailed patches by inferring what the model knows about expected retinal anatomy. We have proven that, using a minimal dataset of specific OCT scans, we were able to generalize and have a super-resolutional model with good results..
It is also very sensitive to check the loss function and adjust it to the specific case of OCT images, which abound in stain-like textures stemming from speckles that are not meaningful. The algorithm engineer has to adjust the loss function accordingly.
RSIP Vision has developed a very precise super-resolution algorithm for OCT. Contact us to check how we can use it for your AI project in ophthalmology.
 Ophthalmology
Ophthalmology