Recent works suggest novel deep learning tools for detection, segmentation and characterization of eye disorders. Accurate segmentation of retinal fundus lesions and anomalies in imaging data is an important technical step for early detection and treatment of common eye disorders, and a central algorithmic challenge for supervised learning approaches in this context if the sparsity of labeled data. We review several new works that suggest new tools and network architectures as deep learning in ophthalmology models to deal with this problem.
[4] suggest a semi-supervised learning approach for segmentation of the optic cup in retinal fundus images; a variational auto-encoder [3] is trained to learn a feature representation from unlabeled data, and an encoder network is trained on a small number of annotated segmentation images, represented as dense feature vectors from the auto-encoder. They train and validate their model on data from EyePACS with 12,000 fundus images, 600 of which are used as an annotated dataset. This new model achieves a 1% improvement in Dice score over the U-Net CNN when trained on the full dataset, with a score of 80%. Moreover, when the number of annotated examples is smaller the advantage becomes more significant, with 73% vs. 69% compared to the U-Net benchmark. The method may be applicable to other modalities – especially where the segmentation shape has similar features across the data.
[2] take a different approach and suggest to use textual clinical reports as an aid for micro-aneurysms detection in fundus images, for the purpose of early treatment of diabetic retinopathy. The data in this problem usually suffers from a severe imbalance, and the authors suggest to use CNN features together with a key-word based word embedding of the text for the classification task.
Other works on diabetic retinopathy detection are [6] and [7]. [6] use the Inception-Resnet [5] as a main branch network, and add two auxiliary network branches that locate and zoom-in on relevant areas in the image. This attention mechanism, as illustrated in the figure below, may be utilized for other lesion detection tasks. The model achieved 85% recall on the EyePACS dataset.
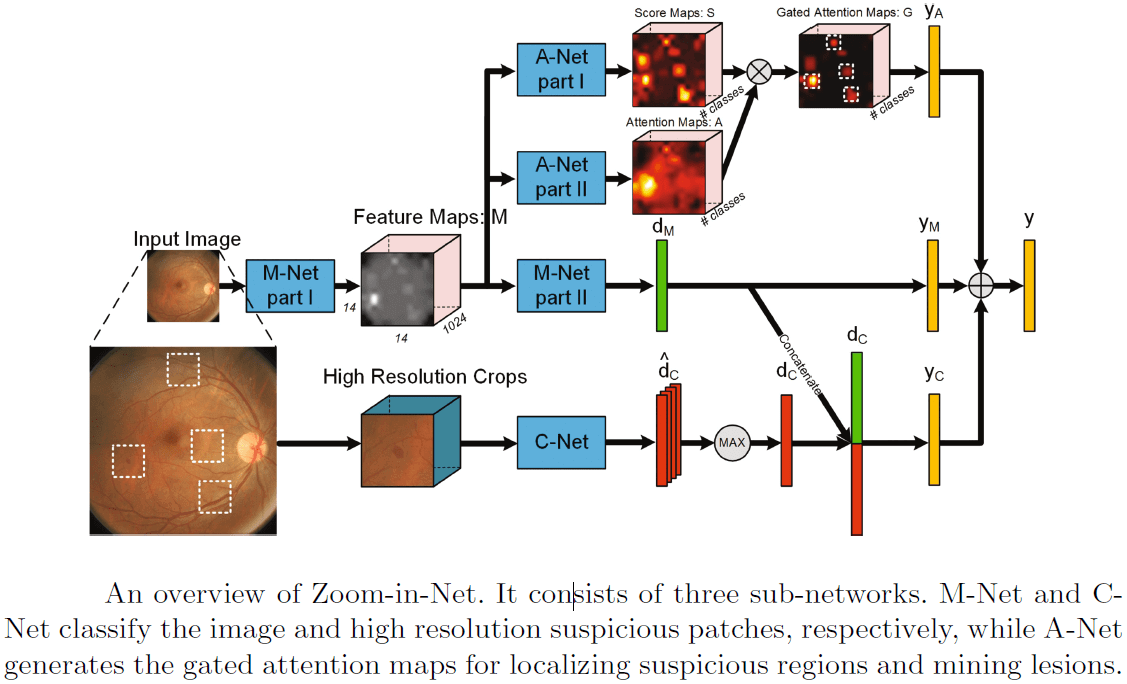
The above illustration of the CNN model from [6] shows that it consists of three sub-networks: M-Net and C-Net classify respectively the image and high resolution suspicious patches, while A-Net generates the gated zoom-in attention maps for localizing suspicious regions.
In [7], a two stage CNN algorithm is utilized to point out the lesions in fundus color images, and to output also severity grades for diabetic retinopathy. They also suggest to use a weighted lesion map to deal with the data imbalance problem; at the first stage, a CNN identifies patches in the images that are suspected as lesions; then, two maps are produced and weighted – a max-probability prediction map and a label prediction map. At the second stage, these two maps are used as input for another CNN. The authors show in the paper that this new deep learning method outperforms SVM and Random-Forest benchmark models.
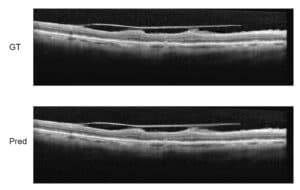
[1] consider the problem of monitoring of eye disorders over time in OCT imaging and focus on late stage disease of Age-related Macular Degeneration (AMD), where segmentation is difficult due to the irregular pathological shapes in the data. They use a network with dilated residual blocks in an asymmetric encoder-decoder architecture which they call Branch Residual U-Network, to segment multiple retinal layers in OCT cross-sections. The difference in architecture from the standard U-Net is mainly in the use of skip-connections between different layers within the encoder branch. The results from this model give a slight advantage over the U-Net in terms of Dice score, with a faster training convergence time and about 30% shorter prediction running time.
Deep Learning in Ophthalmology – References
(*) Descoteaux, M., Maier-Hein, L., Franz, A., Jannin, P., Collins, D.L., Duchesne, S. (eds.) Medical Image Computing and Computer-Assisted Intervention MICCAI 2017. Springer International Publishing, Cham (2017)
[1] Apostolopoulos, S., De Zanet, S., Ciller, C., Wolf, S., Sznitman, R.: Pathological oct retinal layer segmentation using branch residual u-shape networks. Printed in (*) pp. 294–301.
[2] Dai, L., Sheng, B., Wu, Q., Li, H., Hou, X., Jia, W., Fang, R.: Retinal microaneurysm detection using clinical report guided multi-sieving cnn. Printed in (*) pp. 525–532.
[3] Kingma, D.P., Welling, M.: Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114 (2013)
[4] Sedai, S., Mahapatra, D., Hewavitharanage, S., Maetschke, S., Garnavi, R.: Semi-supervised segmentation of optic cup in retinal fundus images using variational autoencoder. Printed in (*) pp. 75–82.
[5] Szegedy, C., Ioffe, S., Vanhoucke, V., Alemi, A.A.: Inceptionv4, inception-resnet and the impact of residual connections on learning. In: AAAI. vol. 4, p. 12 (2017)
[6] Wang, Z., Yin, Y., Shi, J., Fang, W., Li, H., Wang, X.: Zoomin-net: Deep mining lesions for diabetic retinopathy detection. Printed in (*) pp. 267– 275.
[7] Yang, Y., Li, T., Li, W., Wu, H., Fan, W., Zhang, W.: Lesion detection and grading of diabetic retinopathy via twostages deep convolutional neural networks. Printed in (*) pp. 533–540.
 Ophthalmology
Ophthalmology