This article was first published on Computer Vision News of May 2022.

By Ioannis Valasakis
The title of the article is Vision Transformers in Medical Computer Vision, written by Arshi Parvaiz et al from The School of Electrical Engineering and Computer Science in Islamabad, Pakistan and it introduces the readers to what a vision transformer is how’s used as a state-of-the-art approach in medical computer vision and pros and cons which are discussed in depth.
One of the reasons for choosing the article this month is my own curiosity on the subject and whether it’s suitable for my own research on explainable classification neuroscience models. Are you curious? Me too!
Here we will give an overview before we start reviewing the article. I hope you enjoy!
Vision Transformers
Vision Transformers (ViTs) are evolved as one of the most contemporary and dominant architectures that are being used in the field of computer vision. These are immensely utilized by many researchers to perform new as well as former experiments. This article investigates the intersection of Vision Transformers and Medical images as an overview of various ViTs based frameworks that are being used by different researchers in order to decipher the obstacles in Medical Computer Vision.
A survey is performed on the application of Vision transformers in different areas of medical computer vision such as image-based disease classification, anatomical structure segmentation, registration, region-based lesion detection, reconstruction using multiple medical imaging modalities that greatly assist in medical diagnosis and hence treatment process, and in the following figure from the paper you can see how different reviews have approached the subject.
Medical images contain an ample information that is the key for medical diagnosis and hence treatment. The healthcare data comprises 90% of imaging data, so considered as the primary source for medical intervention and analysis. Multiple medical imaging modalities such as Computed Tomography (CT), ultrasound, X-ray radiography, MR Imaging (MRI), and pathology are commonly used for medical imaging diagnostics. The analysis of these images by analysts is limited by human subjectivity, time constraints, and variation of interpretation.
Several challenging factors associated with medical imaging modalities such as expensive data acquisition, dense pixel resolution, lack of standard image acquisition. Those techniques in terms of tool and scanning settings, modality-specific artefacts and hugely imbalanced data in negative and positive classes are major hindrance in translating AI based diagnosis into clinical practice.
Convolutional Neural Networks (CNN) are a type of deep learning architecture. CNNs are potentially the most popular deep learning architecture for its distinguished capabilities to exploit the spatial and temporal relationship between the features of images. CNNs have achieved notable accomplishment in medical imaging applications, such as, determining the presence and then identifying the type of malignancy (Classification), locating the patient’s lesion (Detection), extracting the desired object (organ) from a medical image (Segmentation), placing separate images in a common frame of reference for comparing or integrating the information they contain (Registration), synthesizing images for balancing dataset (Generative Modeling). CNNs are very good at feature extraction tasks.
CNNs lose the global context of the features. Increasing the number of filters improves the representation capacity but at the cost of computation. Various architectural changes are suggested by researchers for an efficient solution over time and leading to attention mechanisms. Using attention mechanism, regions of the image are captured, to which a CNN should pay attention, and forwarded to deeper layers. Researchers have demonstrated that replacing convolutional layer with attention has improved performance. It gets the best out of the attention mechanism to incorporate global context in the image features without compromising computational efficiency.
The potential of the vision transformers is further explored by many researchers for solving various problems. In this work it is highlighted the contribution of vision transformers to circumvent the challenges in automatic diagnostic of diseases using medical imaging modalities and their applications in medical computer vision tasks.
Medical images are used for medical diagnosis and treatment. Medical images can be acquired by various modalities, such as computed tomography (CT), ultrasound, X-ray radiography, MR imaging (MRI), Positron emission tomography-computed tomography (PET-CT), pathology fundus images and Optical coherence tomography (OCT). The images acquired from these modalities are shown in the figure below with more details about these image modalities in the following section.
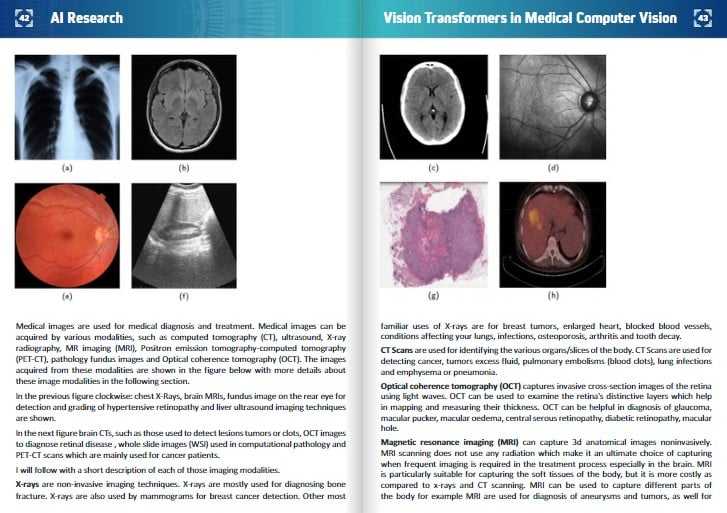 In the left figure clockwise: chest X-Rays, brain MRIs, fundus image on the rear eye for detection and grading of hypertensive retinopathy and liver ultrasound imaging techniques are shown.
In the left figure clockwise: chest X-Rays, brain MRIs, fundus image on the rear eye for detection and grading of hypertensive retinopathy and liver ultrasound imaging techniques are shown.
In the right figure brain CTs, such as those used to detect lesions tumors or clots, OCT images to diagnose retinal disease , whole slide images (WSI) used in computational pathology and PET-CT scans which are mainly used for cancer patients.
I will follow with a short description of each of those imaging modalities.
X-rays are non-invasive imaging techniques. X-rays are mostly used for diagnosing bone fracture. X-rays are also used by mammograms for breast cancer detection. Other most familiar uses of X-rays are for breast tumors, enlarged heart, blocked blood vessels, conditions affecting your lungs, infections, osteoporosis, arthritis and tooth decay.
CT Scans are used for identifying the various organs/slices of the body. CT Scans are used for detecting cancer, tumors excess fluid, pulmonary embolisms (blood clots), lung infections and emphysema or pneumonia.
Optical coherence tomography (OCT) captures invasive cross-section images of the retina using light waves. OCT can be used to examine the retina’s distinctive layers which help in mapping and measuring their thickness. OCT can be helpful in diagnosis of glaucoma, macular pucker, macular oedema, central serous retinopathy, diabetic retinopathy, macular hole.
Magnetic resonance imaging (MRI) can capture 3d anatomical images noninvasively. MRI scanning does not use any radiation which make it an ultimate choice of capturing when frequent imaging is required in the treatment process especially in the brain. MRI is particularly suitable for capturing the soft tissues of the body, but it is more costly as compared to x-rays and CT scanning. MRI can be used to capture different parts of the body for example MRI are used for diagnosis of aneurysms and tumors, as well for differentiating between white matter and grey, in brain. There is a specialized MRI called functional Magnetic Resonance Imaging (fMRI), which is used for observing brain structure and locating the areas of the brain which are activated during cognitive tasks.
Ultrasound can be used to internal organs within the body, noninvasively. Ultrasound images are captured in 2D, 3D, but it can also capture 4D images which is 3D in motion such as a heart beating or blood flowing through blood vessels.
The Whole-Slide Imaging (WSI) refers to capturing the microscopic tissue specimens from a glass slide of biopsy or surgical specimen which results in high-resolution digitized images. Specimens on glass slides transformed into high-resolution digital files can be efficiently stored, accessed, analyzed, and shared with scientists from across the web using slide management technologies. WSI is changing the workflows of many laboratories.
PET scans can be used for cancer detection and diagnosis. PET scans can be used to determine spread of the cancer, determining the recurrence of cancer, metastasis, evaluating brain abnormalities like tumor and memory disorder. PET scans map normal human brain and heart function.
AI and healthcare analysts can use deep learning concepts, techniques, and architectures to bridge the gap between them.
Deep neural networks in computer vision have contributed to various fields of study. For instance, while assessing medical images, practitioners can recognize if there is an anomaly. CNNs generally consist of three kinds of layers: convolution layers, pooling layers, and full-connected layers. Convolution layers are responsible for learning features and capturing the Spatial and Temporal dependencies between the features by application of relevant filters. The pooling layer is responsible for reducing the size of feature maps to capture more semantic information than spatial information. Before the fully connected layer, the output of the convolutional and pooling layer is flattened to make a fully connected layer. A loss function is used to calculate the error and the is back propagated to update the values of learnable parameters. In recent years several CNN architectures are developed with various such arrangements: AlexNet, VGGNet, GoogleNet, ResNet, ResNeXt, Squeeze and Excitation Net, DenseNet, and EfficientNet.
Convolutional neural networks are used in various applications in the categories of image classification, detection, and segmentation, etc. They are known to be a black box, as the training is according to the task and domain. One major limitation is the unclarity of results i.e., the reason for a particular outcome.
One way to tackle this problem head-on is to have such a model that focuses on relevant parts of the image and can be visualized by the doctors. Attention models were proposed. Transformers consist of multiple blocks of identical encoders and decoders, which were composed of self-attention block and feed-forward networks. Transformers consist of an extra attention block, which focuses on the relevant part of the sequence. The performance of the transfer models was state-of-the-art in tasks related to natural language processing.
The model was called Vision Transformers (ViT). They divided the entire image into small image patches of 16×16. They introduced simple numbers 1, 2, up to n as positional embeddings for specifying the positions of the patches.
Vision transformers have the capability of modelling global context which assists in more accurate results. Medical images are considered as the input for vision transformers.
For medical imaging classification the practitioners give their diagnosis by analyzing the medical images. Image classification has various applications in the medical domain. At present, image classification has various applications in the medical domain.
Image classification using CNNs can be used for various applications. The applications were achieved through various CNN architectures such as AlexNet, VGGNet GoogleNet , ResNet. More resource-efficient architectures were proposed i.e. MobileNet, Squeeze and Excitation Net, and EfficientNet.
Convolutional Neural Networks (CNNs) have been the most dominant deep neural networks for autonomous medical image analysis applications such as image classification during the last decade. These models, however, have shown poor performance in learning the long-range information, due to their localized receptive field. Transformer architecture, proposed by Vaswani et al., is currently the most popular model in the field of natural language processing (NLP). Self-attention modules are used in these models to learn the relationship between the embedded patches. In these models, the overall training process is predicated on dividing the input image into patches and considering each embedded patch as a word in NLP. They propose three different approaches to summarization. The performance matrices summarize the performance of each approach. They include a table that summarizes the performance matrix. In the following figure there’s a representation of visual transformers.
Keep reading the Medical Imaging News section of our magazine.