AI and computer vision technologies can significantly improve the quality of surgical procedures by providing tools that help analyze and monitor certain parts of the surgical workflow. Surgical Workflow Analysis and Surgical Instrument Detection are two good examples of applications that lay the groundwork for fully robotic surgery, the next step in computer-aided surgery.
Surgical Workflow Analysis is an innovative approach for following a surgical process with real-time analysis of live video taken during the procedure. It offers an additional layer of quality control and safety to surgical procedures, providing a tool to keeps surgeons and OR staff on track with every small detail.
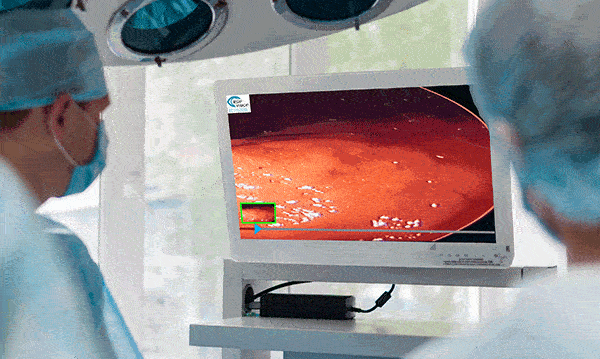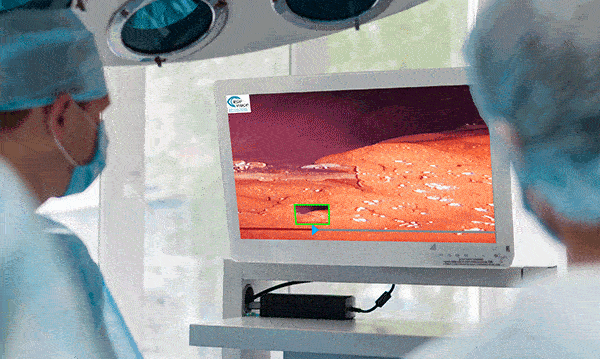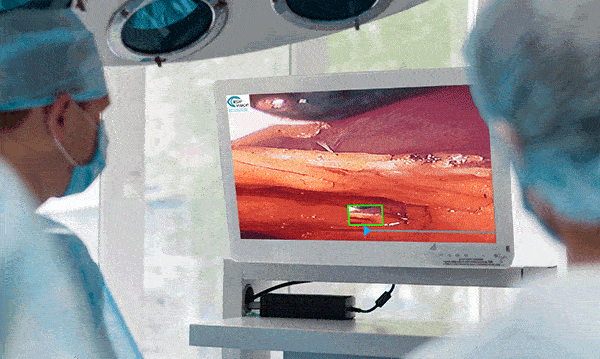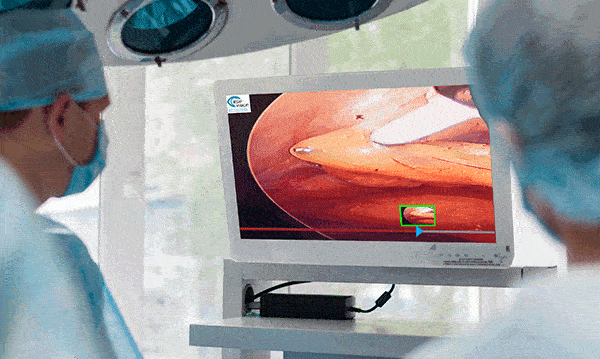
Surgical Workflow Analysis identifies the stages of a procedure, and gives guidance on what tool to use next, what the next step should be, or by displaying pertinent information at any given time. For example, if the operation is to remove a growth and the computer determines that the growth is visible, it will display any information it can gather to aid the surgeon during the procedure.
Surgical Workflow Analysis can also be utilized to assess the remaining time of surgery – information that is important both inside and outside the OR and alert the physician if a procedure is taking too long to perform and notify staff that there will be a delay in starting the next surgery.
It can also be used offline for building a database of video segments, training and quality assessment of the surgeon and surgical teams.
Currently, most Surgical Workflow Analysis software is developed on the basis of visual cues tailored to each procedure, which identify the stage of a procedure by something seen in video, for example the use of a specific instrument. But, replacing these visual cues with deep learning will bring better results.
In the past, deep learning was frame-based; a computer looked at an individual frame without the context of video, and Convolutional Neural Networks (CNNs) were used to analyze each frame and identify to which stage it belonged. Since each frame is part of a sequence, the success of frame-based analysis was limited. Another approach was to compare every two frames, using a Siamese Neural Network to compare frames and decide their correct order.
The more complex and advanced approach is using recurrent neural networks (RNNs), specifically Long Short-Term Memory (LSTM) networks which analyze a temporal sequence of frames and look for specific cues in throughout the entire temporal sequence. More advanced approaches also use a 3D CNN to analyze the video as a whole and find correlations, then implement a LSTM network to decide what stage the video is showing.
“LSTMs are tricky to train and use,” says Daniel Tomer, Algorithm Team Leader at RSIP Vision. “The recurrent nature of the model makes it harder to visualize and as opposed to feed forward CNNs, there is more than one way to use the model for inference. You can feed the model batches of frames and get a prediction for all of them at once, or choose to use the prediction of only the last frame of each batch. You can also feed one frame one at a time and continuously update the inner state of the model throughout the entire process. From our experience at RSIP Vision, we found that no method is better than others, each task has its unique challenges, and these can each be solved using a different inference procedure.”
 Endoscopy
Endoscopy