This article was first published on Computer Vision News of November 2021.
Dominik Rivoir is a PhD student at the National Centre for Tumor Diseases, under the supervision of Stefanie Speidel. His work proposes a new approach to providing simulated 3D data in a surgical setting. It has been accepted as a poster at ICCV 2021 and Dominik spoke to us ahead of his live Q&A session.

Computer-assisted surgery involves analyzing video feed from the surgery to provide feedback. This may be to identify structures, like organs or unsafe regions the surgeon should stay away from, or to recognize instruments to understand what the surgeon is doing.
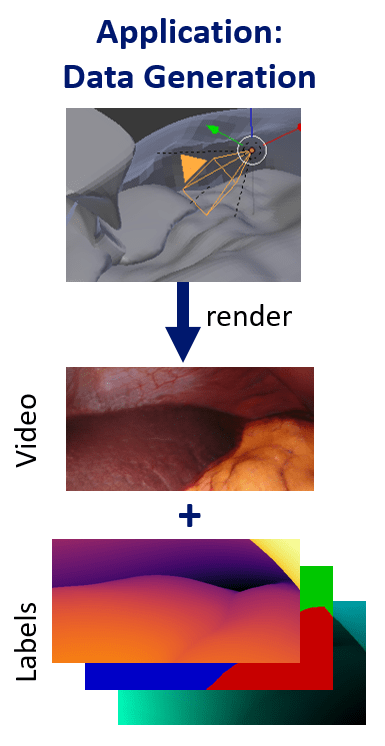
One of the biggest challenges in the surgical setting is the lack of labeled data. Obtaining labeled video data in the surgical setting, such as point correspondences over time, or training 3D information like depth or 3D positions, is especially difficult. This work aims to solve that by providing synthetically rendered, but realistic looking data, with the goal of achieving view-consistency, or longterm temporal consistency, in the generated videos.
“This work is a mix between GAN-based translation, which has been a big focus for a few years now, and the more recent field of neural rendering,” Dominik explains.
“Neural rendering is where we take traditional rendering pipelines from computer graphics and try to make them differentiable and incorporate neural networks. We take the 3D information that we have from our simulated scene and try to incorporate that into the learning process.”
Obtaining the data needed for this was, as ever, a challenge in the surgical domain, as was finding the corresponding real data and simulated data. The team had to design a simulated scene that somehow resembled the realistic data. For that, they had to build the scenes first and then extract all the 3D information from that and design the model on top.
“We use something called a neural texture,” Dominik explains. “We have a 3D representation of the entire scene’s texture. In traditional computer vision, at each texture location in the scene you would store something like the color of the object that you want to render, then how it reflects, something like that. But we want to learn these features and not explicitly define them, so at each spatial location on the texture we have a learnable feature vector, and we project those feature vectors from 3D into 2D space when we want to capture an image. Then we use a neural network to translate these abstract features into an image. Since this whole pipeline including the projection into 3D space is differentiable, we can just learn the network combined with the neural texture together.”
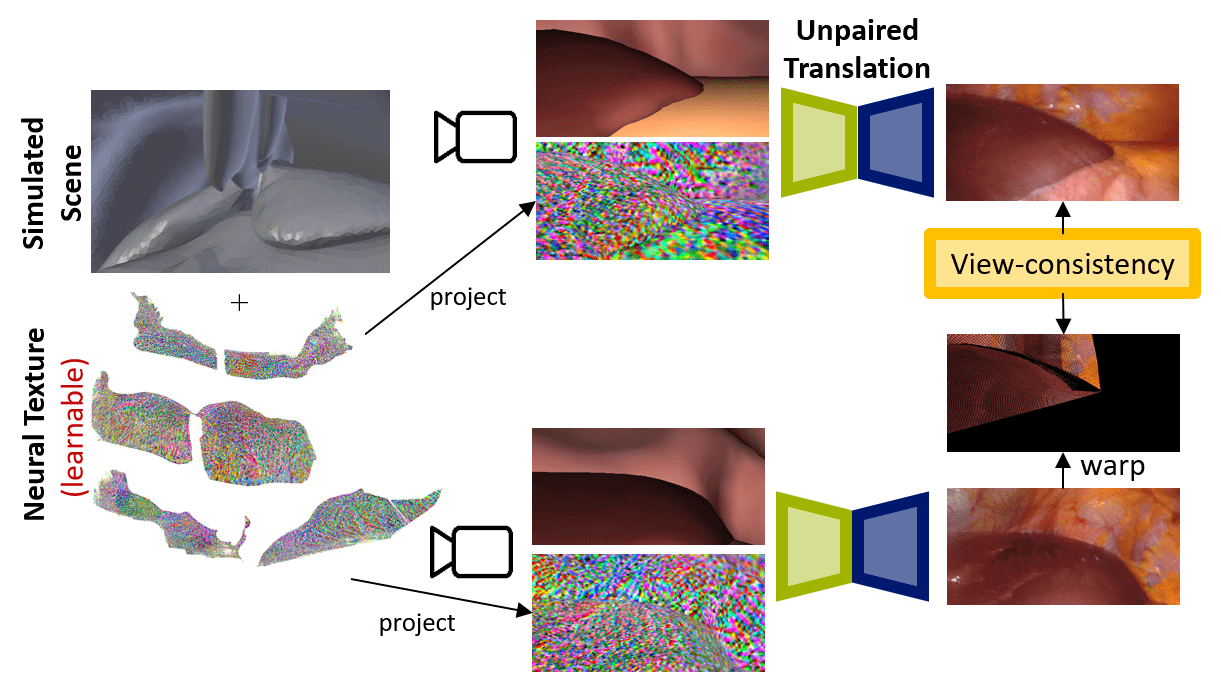
The neural texture enables the model to store global information about the scene, such as the location of vessels, in 3D space and thus these details can be rendered consistently across different viewpoints.
One of the work’s main achievements was combining the two areas of neural rendering and image translation. In image translation, there has been a lot of work done on unsupervised learning, but in neural rendering, that is not really the case. In neural rendering, people have been doing amazing research in how to make this pipeline differentiable, but they have been looking at the supervised setting. Dominik and his colleagues have been trying to combine these two areas and make the 3D neural rendering unsupervised also.
He thinks the work could have an impact in the real world sooner rather than later.
“We’re not directly designing an assistance system, but rather we’re providing the data to evaluate or to train other systems,” he tells us. “We’re providing an evaluation platform for other methods. We hope that this way we can help other researchers show their methods are useful. In turn, that will support better translation.”
In terms of next steps for this work, one issue with the current method the team would like to solve is that it always has to make some assumptions, particularly in the unsupervised setting, to make sure that what it’s learning or what the model is translating is useful. The 3D shapes have to be modeled and the model fails as soon as the 3D shape is not realistic. A future direction for the work could be to look at lessening those restrictions and trying to incorporate learning the 3D shapes or other assumptions that are being made.
We cannot let Dominik leave without asking him about working with Stefanie Speidel, who regular readers will know is a dear friend of our magazine. “It’s really amazing to work with Stefanie!” he smiles. “She’s one of the pioneers in the surgical assistance field and has so much experience. On the one hand, she knows what’s important and can lead you in which direction to go, but on the other, she provides a lot of freedom in terms of which way you want to go. She’s always there to guide us and make sure we’re going in the right direction. It’s a great mix of having the freedom to work on what you’re passionate about but also having somebody who has all this experience to supervise it. I’m very happy here!”
Keep reading the Medical Imaging News section of our magazine.
Read about RSIP Vision’s R&D work on the medical applications of AI.