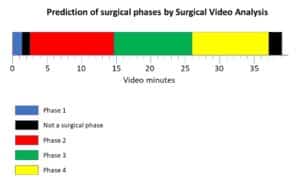
Testing a set of images for similarity has long been a task of image processing computer vision and machine learning. The plethora of tools and techniques suggested to treat such task stems from the ever expanding definition of similarity. For some applications, similarity in color might suffice; whereas for others, categorical similarity is demanded. Such is the case for categorization or labeling video sequences or clustering images displaying a particular motion, while subjects vary in appearance between images.
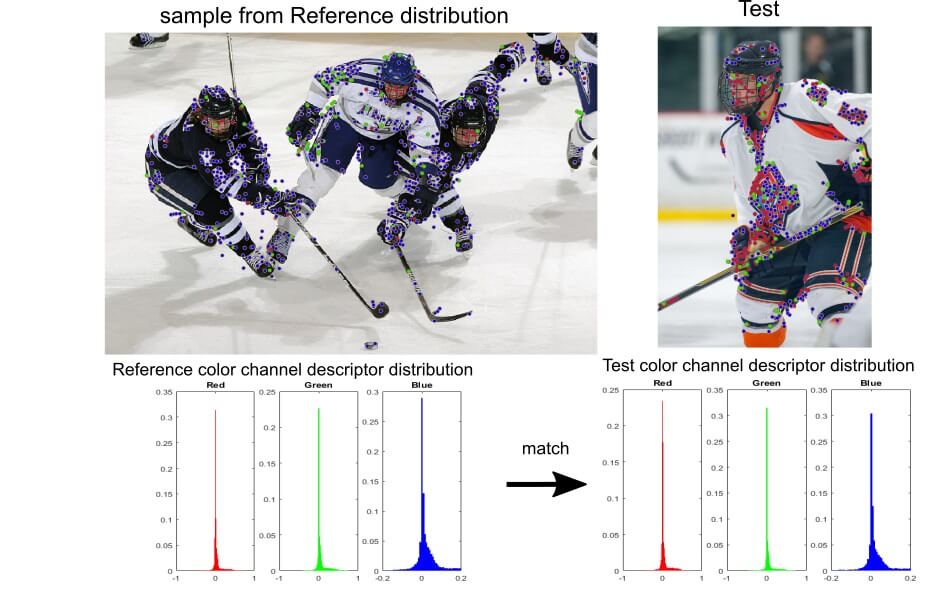
Many techniques have been developed over the past few decades to perform scene analysis, categorization and retrieval. Many of which extract, track, and analyze features and their descriptors within each image to form as an initial data set for both deterministic and statistically based (learning) algorithms. The cost of such analysis in terms of development and running time might exceed the threshold requirement, while often times its performance is at par with algorithms working on broader characteristics of images and their descriptors.
One form of general image descriptor is a statistical measure called Fisher Kernel. Fisher Kernel allows to compute a measure of similarity between images by maximizing the likelihood they belong to one of several predefined classes. The distribution of descriptor values is matched a-priori by learning techniques. Large collection of images are labeled and maximum likelihood estimators are calculated for the distributions’ parameters. A popular choice for the prior class descriptor distribution is Gaussian mixture, composed of multiple mixed Gaussians. Multitude of Gaussians can be viewed as a collection of words, in analogy to the Bag-of-words classification methodology.
To assign a class to images, features and their descriptors are initially extracted. Then, the distribution of the descriptor values is calculated and tested for similarity to one of the predefined class prior distributions by computing the Fisher kernel. The Fisher kernel can thus be viewed as a distance measure between the descriptor values of each image based on the mutual information of the prior classes’ descriptors distribution. Maximization is done on a set of parameters arranged in a vector form and termed Fisher Vectors (FV). Similarity (or distance) measure between Fisher Vectors can be performed in several ways, among others the dot product (a relatively cheap operation), or the cosine measure can be used.
In practice, there is no restriction to the choice of features to be calculated in each image. It is only important that their descriptors will be comparable, that is, matching the same type of descriptors to the fitted distribution of the prior classes. One advantage of the Fisher vectors for image retrieval is their ability to reduce the influence of background descriptors appearing frequently in a class of images (giving a suitable normalization). One disadvantage is the relative large size of these vectors. Binning of the Fisher Vectors or spectral hashing can take place to reduce the computation and analysis load by reducing the FV dimensionality.
The result of the methodology briefly outlined above is the ability to assign a class to an image based on learning methodologies, and as such have the ability to compare a set of images. Image retrieval – finding an image in a database based on its visual similarity to a reference – can thus be used to automatically label a new image (the new item problem) for recommender systems, and further be used in video to find matched sequences of interest or label activity therein. Fisher vectors forms as a global descriptor of the image, incorporating the distribution of many features found within it. However, applying FV analysis on parts of images can also be performed. This allows to compare different segments of the same scene.
Methodologies such as Bag of Words (see Computer Vision News of June 2016) and Fisher vectors for image and categorization retrieval are relatively new in the computer vision community. Indeed, such methodologies are improved and integrated with other tools to perform harder and more complex tasks. At RSIP Vision we are fast to adopt new developments in algorithmic solutions, in order to always offer our clients cutting edge effective solutions.
One form of general image descriptor is a statistical measure called Fisher Kernel. Fisher Kernel allows to compute a measure of similarity between images by maximizing the likelihood they belong to one of several predefined classes. The distribution of descriptor values is matched a-priori by learning techniques. Large collection of images are labeled and maximum likelihood estimators are calculated for the distributions’ parameters. A popular choice for the prior class descriptor distribution is Gaussian mixture, composed of multiple mixed Gaussians. Multitude of Gaussians can be viewed as a collection of words, in analogy to the Bag-of-words classification methodology.
To assign a class to images, features and their descriptors are initially extracted. Then, the distribution of the descriptor values is calculated and tested for similarity to one of the predefined class prior distributions by computing the Fisher kernel. The Fisher kernel can thus be viewed as a distance measure between the descriptor values of each image based on the mutual information of the prior classes’ descriptors distribution. Maximization is done on a set of parameters arranged in a vector form and termed Fisher Vectors (FV). Similarity (or distance) measure between Fisher Vectors can be performed in several ways, among others the dot product (a relatively cheap operation), or the cosine measure can be used.
In practice, there is no restriction to the choice of features to be calculated in each image. It is only important that their descriptors will be comparable, that is, matching the same type of descriptors to the fitted distribution of the prior classes. One advantage of the Fisher vectors for image retrieval is their ability to reduce the influence of background descriptors appearing frequently in a class of images (giving a suitable normalization). One disadvantage is the relative large size of these vectors. Binning of the Fisher Vectors or spectral hashing can take place to reduce the computation and analysis load by reducing the FV dimensionality.
The result of the methodology briefly outlined above is the ability to assign a class to an image based on learning methodologies, and as such have the ability to compare a set of images. Image retrieval – finding an image in a database based on its visual similarity to a reference – can thus be used to automatically label a new image (the new item problem) for recommender systems, and further be used in video to find matched sequences of interest or label activity therein. Fisher vectors forms as a global descriptor of the image, incorporating the distribution of many features found within it. However, applying FV analysis on parts of images can also be performed. This allows to compare different segments of the same scene.
Methodologies such as Bag of Words (see Computer Vision News of June 2016) and Fisher vectors for image and categorization retrieval are relatively new in the computer vision community. Indeed, such methodologies are improved and integrated with other tools to perform harder and more complex tasks. At RSIP Vision we are fast to adopt new developments in algorithmic solutions, in order to always offer our clients cutting edge effective solutions.