![]()
One line of solutions for non-rigid object tracking utilized a per-frame search algorithms to locate the goal object using learned object’s features and connect them temporally over frames. However, solutions of this kind tend to be computationally prohibitive in real-time applications and are prone to failure when multiple objects of the same nature appear in the image. Furthermore, the use of features to identify non-rigid objects demands a spatio-temporal relationship between features found in each frame. This top-bottom approach is frequently used for human body tracking, where a deformable skeleton template with predefined mechanical limitations is fitted to features found per-frame in a video sequence.
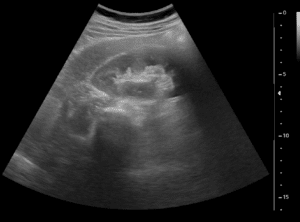
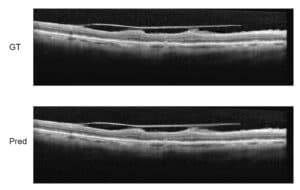
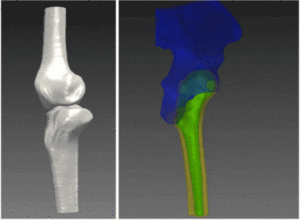
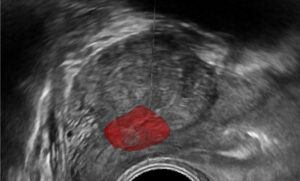
Thus, in all natural videos sequences we expect some degree of deformable objects, non-rigid motion and occlusion. Objects in each frame can be identified by their bounding box, which introduces the risk of capturing features belonging to the background, or by localizing a mask around the object in each frame when objects do not fill the major part of bounding boxes. The later approach is usually more computationally and algorithmically complex than the first, but it offers higher true-positive rate.
With the rapid advances in machine learning techniques during the past decade, it is now possible to reduce computational and algorithmic costs for object tracking. In other avenues, algorithms for objects’ bounding boxes suggestion for detection (such as YOLO, R-CNN and SSD algorithms) have demonstrated a significant improvement in running time. Recent developments in Generative Adversarial Networks (GAN) now offer a promising approach, one which provides the most adequate mask (in feature space) to an object during tracking and one that will persist the longest time (temporally); that is, with the least amount of adjustments over frames and the most persistent features.
The idea behind Generative Adversarial Networks:
GANs are constructed from two deep convolutional neural networks, one generative and the other discriminative. The goal of the generative network is to learn the distribution space of the input data and generate synthetic data samples, which are closest to the one coming from the input distribution. These synthetic sample images are fed passed to the discriminative network, which tries to figure out whether they come from the true data set or are synthetic. In other words, the goal of the generative network is to fool the discriminative network, such that it can no longer distinguish between true and synthetic data.
How is the idea behind Generative Adversarial Networks harnessed to improve object tracking? In object tracking, sampled points around the goal objects contain a dense set of overlapping points and features, which makes it hard to learn the true variability of the object, hence reducing tracking quality. The training data, therefore, needs to be amplified to account for as many object shapes as possible. By training a network on a tight mask of the object, generated by a generative network, the training data is amplified. The mask produced is therefore one which contains the most predictive features while discarding other ones, and one which persists the longest time without adjustments. Using such masks, data fed into the tracker needs to handle less false positives during the classification process, so that later it reduces the burden in the classification of whether a point (feature) in subsequent frames belongs to the goal object or not.
Augmentation of training data set is an important stage in machine learning based tasks, specifically when annotated data are sparse. It is therefore important to put emphasis on training in the construction of computer vision and machine learning solutions. At RSIP Vision we employ cutting edge methodologies to bring our client high-quality tailor-made solutions to their challenges. To learn more about RSIP Vision activities, please visit our project page. To consult our specialists for your computer vision project, please fill this simple contact form.