Part 1: Introduction
From DICOM Chaos to Training-Ready Data: Why the Dataset Pipeline Is the Real Model
If you’re building algorithms in medical AI, you’ve probably lived through some version of this:
- You introduce a new model architecture and performance improves by 3%… then drops by 6% next run.
- A “simple” dataset addition triggers weird errors… or worse, silent failures.
- Your validation curve looks like it’s responding to moon phases rather than learning.
- You spend days debugging training… only to discover labels were shifted by two slices.
And after enough cycles of this, a hard truth starts to form:
In medical AI, model development is often limited less by the model – and more by the dataset pipeline behind it.
This isn’t a trendy “data is the new oil” statement. It’s an operational reality.
Your model can be brilliant. Your training loop can be clean. Your architecture can be state-of-the-art. But if your dataset pipeline is fragile, inconsistent, or untrusted – you’re not really doing machine learning.
The rest of this series describes a dataset pipeline we’ve found reliable and scalable across real-world medical datasets — messy ones. DICOM-heavy ones. Multi-site ones. Clinician-labeled ones. The kind that rarely behave like tidy academic benchmarks.
The pipeline is simple in theory, but ruthless in practice:
- Organize – build dataset adapters and convert everything into a uniform “source of truth” format.
- Prepare – transform organized scans + annotations into training artifacts, with heavy sanity checking.
- Validation – treat validation sets as piecewise constant, stable measurement tools.
- Validation + Test – lock test sets late, only after “living the data.”
Each part is a stage where things can go wrong in a different way, and where different safeguards matter.
Why the Pipeline Matters as Much as Training (Maybe More)
Here’s the problem: model iteration is fast. Dataset iteration is slow.
In consumer ML, you can often download more data tomorrow. In medical AI, not so much.
In Medical AI:
- Data is expensive – locked inside institutions, contracts, review boards, and privacy constraints.
- Labels are subjective – two clinicians may disagree, and both may be “right.”
- Distribution shift is guaranteed – hospitals differ, devices differ, protocols differ.
- Metadata is chaotic – hello DICOM, our old enemy.
So the goal isn’t simply “train a model.”
The real goal is to build a system where:
You can add datasets without breaking everything
You can track progress without metric noise
You can detect failures early
And when performance improves… you trust it
That’s exactly what the pipeline is designed to do.
A good pipeline turns the dataset from something fragile and mysterious into something boring and versioned. And boring is good. Because boring pipelines allow interesting models.
A Mental Model: Dataset Pipeline as a Measurement Instrument
Think about building a medical device. You wouldn’t measure blood pressure with a cuff that changes size every week. But that’s a big pain-point when the dataset pipeline changes constantly.
- New datasets appear
- A conversion script gets “improved”
- Someone changes preprocessing to fix one dataset and breaks another
- Labels are updated without versioning
- Validation gets reshuffled
- And suddenly your metric becomes meaningless
What You’ll Get From This Series
This four-part structure isn’t meant to sound sophisticated. It’s meant to be practical.
It’s about building a pipeline that:
- Survives messy edge cases
- Makes datasets plug-and-play
- Prevents silent errors
- Creates trustworthy measurement
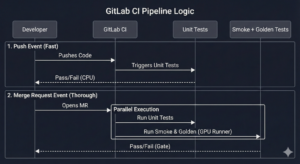
In the next part we’ll start with the first critical step:
Organize – where most of the DICOM pain lives.