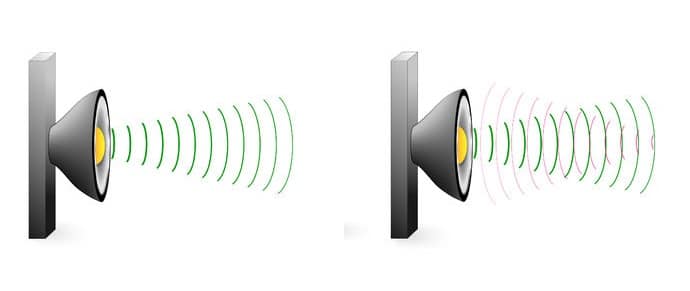
To resolve this issue, acoustic echo cancellation (AEC) algorithms were developed over the past three decades, with the aim of suppressing the acoustic coupling while minimizing the effect on the input speech signal. The measure of this reduction of echo corruption is called the echo return loss (ERL) and it is measured in decibels. Classically, an AEC solution assumes a linear response relationship between the microphone and the loudspeaker, and thus a linear filtering is performed on the input microphone signal to subtract the echo. Such linear relationship is not commonly encountered in real situations, and non-linearities frequently cause speech distortions. The challenge is then to construct an adequate filter to be applied on the signal.
Using deep learning methodologies, the parameters of a non-linear adaptive filter can be learned and used to reduce or completely eliminate echo signal from the desired one. A deep learning architecture allows to resolve the non-linear echo path in low dimensional space into linear high-dimensional space. For this end, a learning set must be generated comprising noisy samples fed back into the input signal and a model response filter, which is aimed at minimizing the ERL and simultaneously complement the signal with the so called echo return loss enhancement (ERLE).
Designing an optimal architecture for such deep learning network is not trivial and it depends heavily on the microphone configuration and on the designated working environment. A cost-effective and reliable solution based on machine learning is the primary expertise of RSIP Vision’s engineers. At RSIP Vision, we have been developing cutting edge, tailor-made machine learning solution for several decades. To learn more on how RSIP Vision’s technologies can be of use in your next signal processing project, please visit our project pages.