Itai Weiss
Continuous Integration (CI) is the practice of automatically testing your code every time you make a change. In traditional software, this works well because the same input always produces the same output. But AI systems break this easily—even just adding more training data without touching the code can cause your tests to fail. After months of dealing with random test failures, most engineers quietly adopt the same survival tactic: ignore CI.
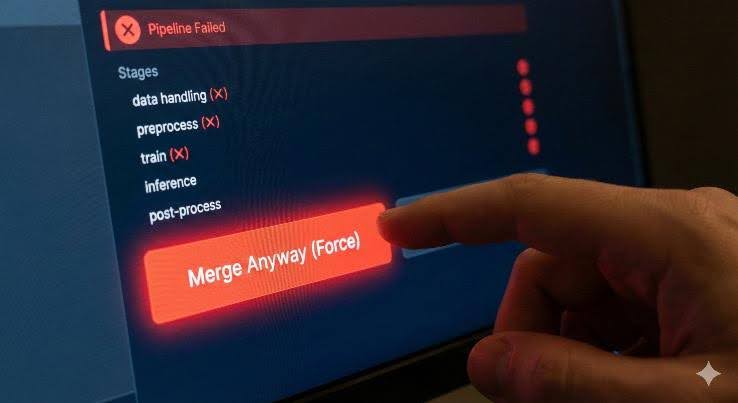
That’s dangerous. When CI becomes unreliable, engineers stop trusting it. That’s worse than having no CI at all. This post presents a practical framework for testing an AI codebase in a way that is stable, fast, and relevant.
What Are We Testing?
Your AI codebase isn’t just a model—it’s an entire system. It includes data readers, preprocessors, training logic, inference wrappers, post-processing rules, and production APIs. This ecosystem needs software-grade testing, even if the model itself isn’t deterministic.
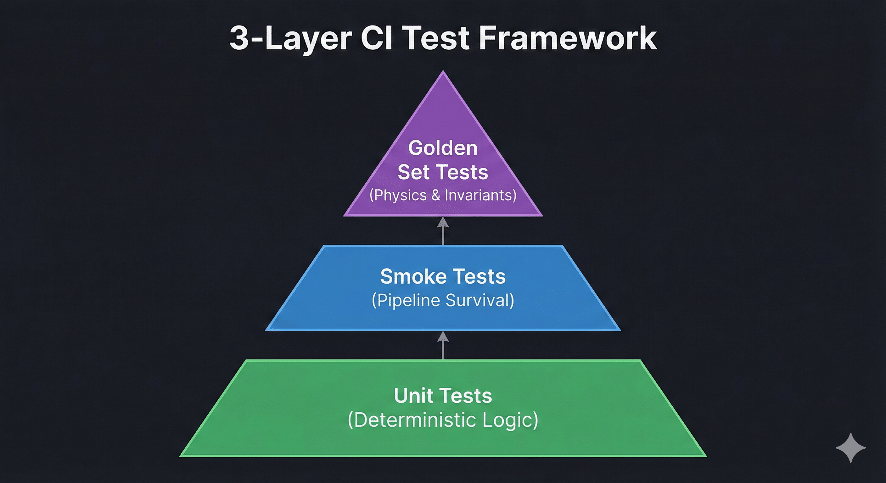
The 3-Layer Test Framework
1. Unit Tests
These are your anchors—the most boring, stable, predictable tests in your system. They cover things like shape checks, tokenizers, normalization operations, custom loss functions, and metric implementations. Unit tests should never depend on data randomness, model weights, or training. They run on every commit and should rarely need updates.
2. Smoke Tests
Smoke tests answer one question: does the entire pipeline still run without crashing? This includes loading a tiny dataset, running a couple of training steps, performing inference, and returning a sane output. We’re not validating accuracy—we’re validating survival. If your smoke test fails, someone broke a core flow. These catch most “oops I refactored preprocessing” bugs. They’re cheap enough to run on every merge request.
3. Golden Set Tests
This is the key layer. The idea: a tiny, fixed, hand-curated dataset combined with behavioral invariants that must always hold. This dataset doesn’t change—it’s your ground truth sanity anchor.
The invariants come from two sources. First, universal AI rules: loss should decrease when training on a small subset, the model should be able to overfit tiny data, and outputs must be sane (no NaNs, predictions aren’t constant). Second, domain-specific rules: in segmentation, golden images have objects of known size, so predictions must preserve those size constraints. In classification, the model must beat random chance.
These invariants survive metric changes, post-processing changes, and even architecture changes—because they reflect the physics of your domain, not the specifics of a model.
Conclusion
With this framework, CI becomes meaningful again. Unit tests catch code bugs, smoke tests catch integration breaks, and golden tests catch AI-specific regressions—all without the false alarms that made you stop trusting CI in the first place.
In Part 2, we’ll show how to implement this using GitLab.