As endoscopic and microscopic image processing, and surgical vision are evolving as necessary tools for computer assisted interventions (CAI), researchers have recognized the need for common datasets for consistent evaluation and benchmarking of algorithms against each other. The Endoscope Vision Challenge (EndoVis), led by Stefanie Speidel, Lena Maier-Hein and Danail Stoyanov and presented at MICCAI 2019, was designed to address this through three sub-challenges: Robust Medical Instrument Segmentation; Stereo Correspondence and Reconstruction of Endoscopic Data; and Surgical Workflow and Skill Analysis.
In this article, Daniel Tomer, AI Team Leader at RSIP Vision, and an expert in algorithm development for endoscopy, explains the three challenges, and gives insight into how solving these problems will dramatically improve the efficiency and accuracy of this type of surgeries.
Robust Medical Instrument Segmentation
Overview
One of the difficulties in the development of robotic assisted intervention systems for laparoscopic surgery is detecting and segmenting the surgical instruments present in the frame. In this challenge, teams attempted to develop robust and generalizable algorithmic models which will solve?
The challenge was divided into three tasks:
1. Binary classification of each pixel as either a background or a tool.
2. Detection using a unique bounding box for each tool that is present in the frame.
3. Instance segmentation, which is similar to binary segmentation, but has a different label for each tool in the frame.
Technical Challenges
There are two main challenges in tool detection and segmentation: The first is making them robust for poor quality frames (due to smoke, motion blur, blood etc., and the second creating a model able to produce accurate predictions on surgery data collected from both a surgery type , and a setting other than the data which was used to train it. These two challenges are true in almost any AI computer vision challenge, however in most cases each domain has its own unique solution.
Results
All state of the art methods for tool segmentation involve the usage of deep neural networks. Best result for off-line (non real-time) prediction achieves an average ~95% dice score. It does so by using a U-Net model with a combination of attention blocks used at the decoding stage, allowing the model to learn what area of the image it can ignore. Transfer learning (pre-training on ImageNet) and custom loss function (combination of cross entropy and dice loss) are also used to achieve this result.
Depth Estimation from Stereo Camera Pair
Overview
Depth estimation is an important component of many endoscopic navigation and augmented reality guidance systems. A stereo camera pair which is comprised of two cameras capturing the scene from two different angles, can be used to obtain a deep image, i.e the depth coordinate of each pixel in the frame.
Technical Challenges
Classical methods which were developed to work on natural image data, do not work well in endoscopic data due to the directional light, non-planar surfaces and subtle texture present in the data but not in natural images.
Methods
Several approaches can be taken to overcome these challenges. The more direct approach is to pre-process the data, so it is more similar to natural images. This can be done by using contrast enhancement methods to make the texture less subtle, and advanced filtering methods to get rid of directional light. After the post-processing, the frames are fed into one of the classical depth estimation methods. While this approach does yield good results, it is not considered as state of the art.
The second approach which aims to achieve state of the art results, is a deep learning end-to-end approach. With this method, a deep convolutional neural network is developed with an architecture specifically aimed to analyze a stereo pair (PSMN for example). The model is trained on simulated data, so that later when it is has fed two images, it will accurately predict their corresponding depth map.
Results
In this sub-challenge, the submitted algorithmic models were evaluated over a test set which consisted of frames taken from an endoscopic camera with an associated ground truth for the depth (which was obtained using a structured light pattern). The metric for evaluation was the per-pixel mean squared error between the ground truth depth image and the predicted one.
Trevor Zeffiro from RediMminds Inc., USA, who came in in first place reached an average of ~3 mm error using the deep learning approach. In second place, Jean-Claude Rosenthal – Fraunhofer Heinrich Hertz Institute, Germany reached an average of ~3.2 mm error using the pre-process approach.
Surgical Workflow Analysis and Skill Assessment
Overview
An essential part of many applications in Computer-Assisted Surgery (CAS) is analyzing surgical workflows, for example specifying the tool most probable to be required next by a surgeon, navigation information, or determining the remaining duration of surgery.
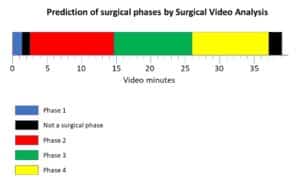
This challenge focused on the real-time workflow analysis of laparoscopic surgeries. Participants were asked to develop models that will be able to temporally segment surgical videos into the surgical phases, to recognize surgical actions and instruments presence and to classify surgical skills based on video data.
Technical Challenges
As in any endoscopy-related tasks, most challenges stem from the fact that endoscopic data is very different than natural images. In addition, the fact that endoscopic datasets are usually small compared to natural image datasets, poses a difficulty in producing robust models.
Another challenge more specific to this particular task, is the importance of the temporal dimension, i.e. one frame is not enough, and video analysis is required.
In order to help the surgeon during the procedure, real-time performance of the algorithm is required. Furthermore, many of these frames will be of low quality due to occasional motion blur and overexposure. A robust model will be required to deal with such cases without harming performance.
Methods
Deep learning models are used in all current state of the art methods. The general approach is to use a convolutional neural network (CNN) such as ResNet-50 or VGG16, in order to extract features from each frame. Features are then used in several different ways, in the different tasks. For tool detection, features are fed into an additional CNN in order to output the location and type of tool. For action and phase recognition, features are used as input for a Long Short -Term Memory (LSTM) model, the most commonly used recurrent neural network. The LSTM receives the output of the previous frame as an input (all besides the features of the current frame) and utilizes the temporal dimension of the video.
Highly ranked competing teams also used models which perform more than one task simultaneously. The rationale behind this is was that when two tasks are related, they may share a feature extractor, thus enabling it to be trained on more data.
For the phase segmentation task, teams also relied on the fact that there is a certain level of prior knowledge regarding the possible order of phases (sine one phase can’t appear before the other) to boost the performance of their models. One team used the elapsed time of each frame as a direct input to the LSTM, which allowed them to gain prior knowledge. Another team used a hidden Markov chain with hard coded probabilities of transitions between phases, to directly impose the prior knowledge.
Results
In this challenge, the submitted algorithmic models were evaluated over a test set which consisted of nine annotated videos of laparoscopic surgery. The videos were annotated by one or more experts, according to the difficulty of the task.
Models were evaluated using the F1 metric. For the tool presence detection task, the best model was able to get a 64% average F1. For the phase segmentation, the best model was able to get a 65% average F1.