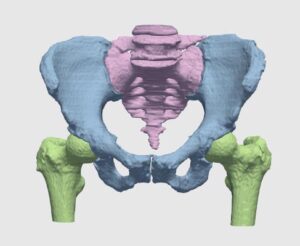
Orthopedic surgeries are one of the most common surgeries in clinical practice. According to recent surveys, more than 300,000 hip replacement and 700,000 knee replacements are performed annually, with frequent treatment of other joints, e.g. shoulder and ankles. With figures on the rise, the burden on orthopedists is increasing, and added load is caused by the demand for secondary procedures to replace worn-out implants and fix implant misfits.
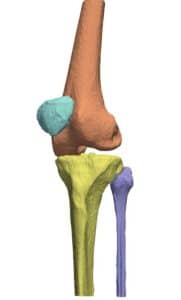
Bottlenecks in orthopedic procedures span across each of its primary steps, namely examination, planning and operation. Incorporation of new visualization technologies and planning methodologies have been shown to shorten the aforementioned steps, while retaining the high standard of accuracy that are required in these common practices. Innovative algorithmic techniques, relying on image processing, computer vision and machine learning are increasingly utilized in practice and have been gaining approval by regulatory bodies such as the FDA, into what is better known as Computer Assisted Orthopedic Surgery (CAOS) procedures.
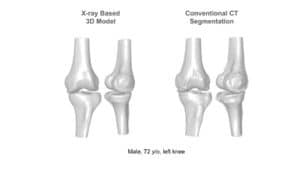
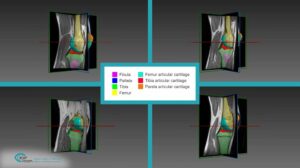
One of the most fundamental tasks in CAOS is the segmentation of bone and cartilage structures in two and three-dimensions. Ideally, automatic or semi-automatic algorithms should operate in a low radiation range, which poses minimal risk to both doctors and patients during imaging. Reduced exposure time correlates with a low signal to noise ratio (SNR), which makes it difficult to interpret images by human eye examination. Image processing and computer vision algorithms should thus be aimed at operating under low SNR in order to highlight, segment and reconstruct relevant structures.
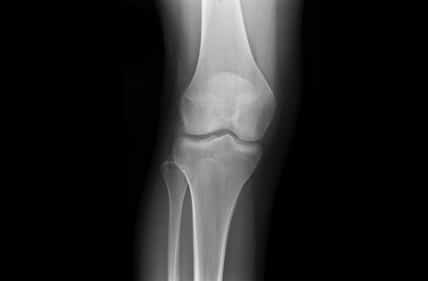
Proximity in the geometric arrangement of bones can pose difficulties for bone segmentation purposes. Specifically, this can be seen on imaging of the knee region. To accurately segment and reconstruct the 3D organization of a rigid structure, a volumetric information must first be obtained by modalities such as magnetic resonance imaging or computational tomography.
Previously, atlas-based methods were a good option for the bone segmentation task, where pre-designed flexible 3D statistical shape models were fitted to the volumetric data by means of optimization methods and their transformation parameters recorded. To assist with fitting, features from the volumetric data were extracted and used for more accurate estimation of the rigid body transformation parameters. At this point, the placement overlying models on the volumetric data might result in erroneous positioning, which needed to be refined by other methods. Boundaries of each bony structure could be extracted from cross-sectional information in the volumetric data. The edges were used to refine the segmentation and increase accuracy of 3D shapes by utilizing algorithms such as the graph-cut.
Currently, the best and most powerful methods for bone segmentation rely on deep learning, with new advancement like shape-aware losses and multi-scale detection and segmentation techniques.
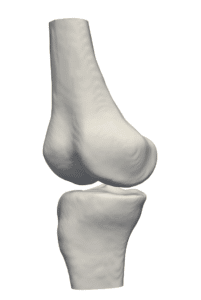
Three-dimensional virtual bone models have great advantages, both in planning a procedure and in the clinical room. The stiff and roughly predictable nature of bones (due to the easier segmentation of rigid bodies) makes them ideal for tracking and for reconstructing a model which can be continuously viewed on screen with instrument overlap (tracked with IR or magnetic means). Such models can perform as the “eyes” of clinicians while carrying out a closed and minimally invasive orthopedic operation.
One of the most fundamental tasks in CAOS is the segmentation of bone and cartilage structures in two and three-dimensions. Ideally, automatic or semi-automatic algorithms should operate in a low radiation range, which poses minimal risk to both doctors and patients during imaging. Reduced exposure time correlates with a low signal to noise ratio (SNR), which makes it difficult to interpret images by human eye examination. Image processing and computer vision algorithms should thus be aimed at operating under low SNR in order to highlight, segment and reconstruct relevant structures.
Proximity in the geometric arrangement of bones can pose difficulties for bone segmentation purposes. Specifically, this can be seen on imaging of the knee region. To accurately segment and reconstruct the 3D organization of a rigid structure, a volumetric information must first be obtained by modalities such as magnetic resonance imaging or computational tomography.
Previously, atlas-based methods were a good option for the bone segmentation task, where pre-designed flexible 3D statistical shape models were fitted to the volumetric data by means of optimization methods and their transformation parameters recorded. To assist with fitting, features from the volumetric data were extracted and used for more accurate estimation of the rigid body transformation parameters. At this point, the placement overlying models on the volumetric data might result in erroneous positioning, which needed to be refined by other methods. Boundaries of each bony structure could be extracted from cross-sectional information in the volumetric data. The edges were used to refine the segmentation and increase accuracy of 3D shapes by utilizing algorithms such as the graph-cut.
Currently, the best and most powerful methods for bone segmentation rely on deep learning, with new advancement like shape-aware losses and multi-scale detection and segmentation techniques.
Three-dimensional virtual bone models have great advantages, both in planning a procedure and in the clinical room. The stiff and roughly predictable nature of bones (due to the easier segmentation of rigid bodies) makes them ideal for tracking and for reconstructing a model which can be continuously viewed on screen with instrument overlap (tracked with IR or magnetic means). Such models can perform as the “eyes” of clinicians while carrying out a closed and minimally invasive orthopedic operation.
 Orthopedics
Orthopedics