















 6 / 56
6 / 56

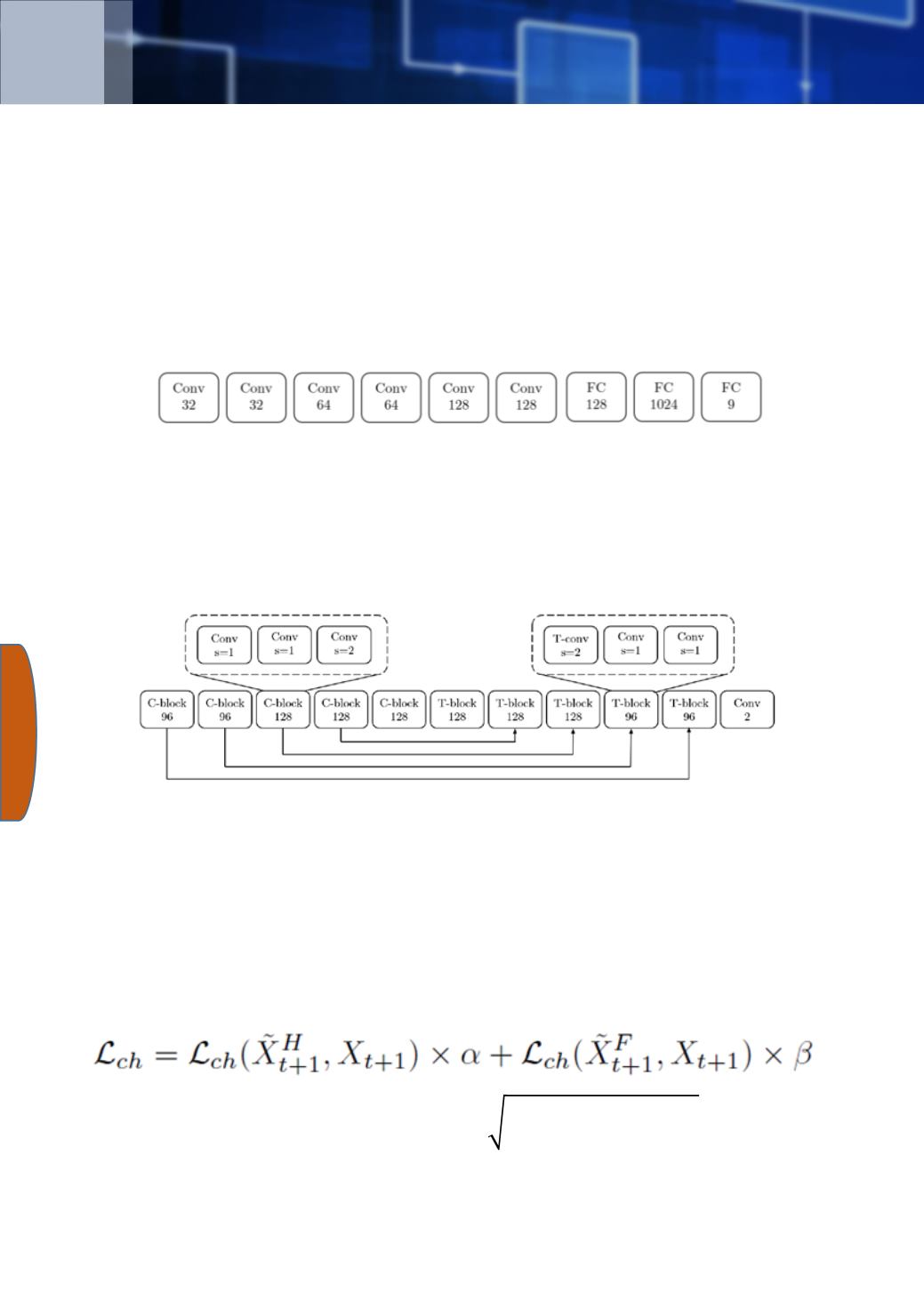
Next is a detailed description of each of the 3 components of the architecture:
(1) The layers of the H-generator network are illustrated below, the H-generator
produces a global flow representing the motion, without the details of
individual objects. During training the H-generator concatenates the two
frames Xt and Xt+1 and outputs the 9 parameters of the homographic matrix
transformation.
(2) The F-generator network layers are illustrated below. The F-generator learns
to refine the flow by taking account of moving objects and fine details
ignored by the H-generator network and at the same time keep a consistent
flow.
The F-generator network has a mirror structure: 5 convolutional layers that
form the encoding block, followed by 5 transposed-convolutional layers that
form a decoder block. Each of the 10 layers includes three 3X3 convolutional
layers with leaky ReLU activations. A final top 2-channel convolution layer
produces the final optical flow in the range of -1 to 1.
The global loss function employed during the training is a weighting the
errors of the H-generator and the F-generator networks.
Where
ℎ
(
+1
,
+1
)
is
(
+1
−
+1
)
2
+
(3) Edge aware smoothing- Edge aware smoothing improves the optical flow
estimation as it allows to get uniform flows within object boundaries, which
6
Computer Vision NewsResearch
Research