















 5 / 56
5 / 56

Computer Vision News
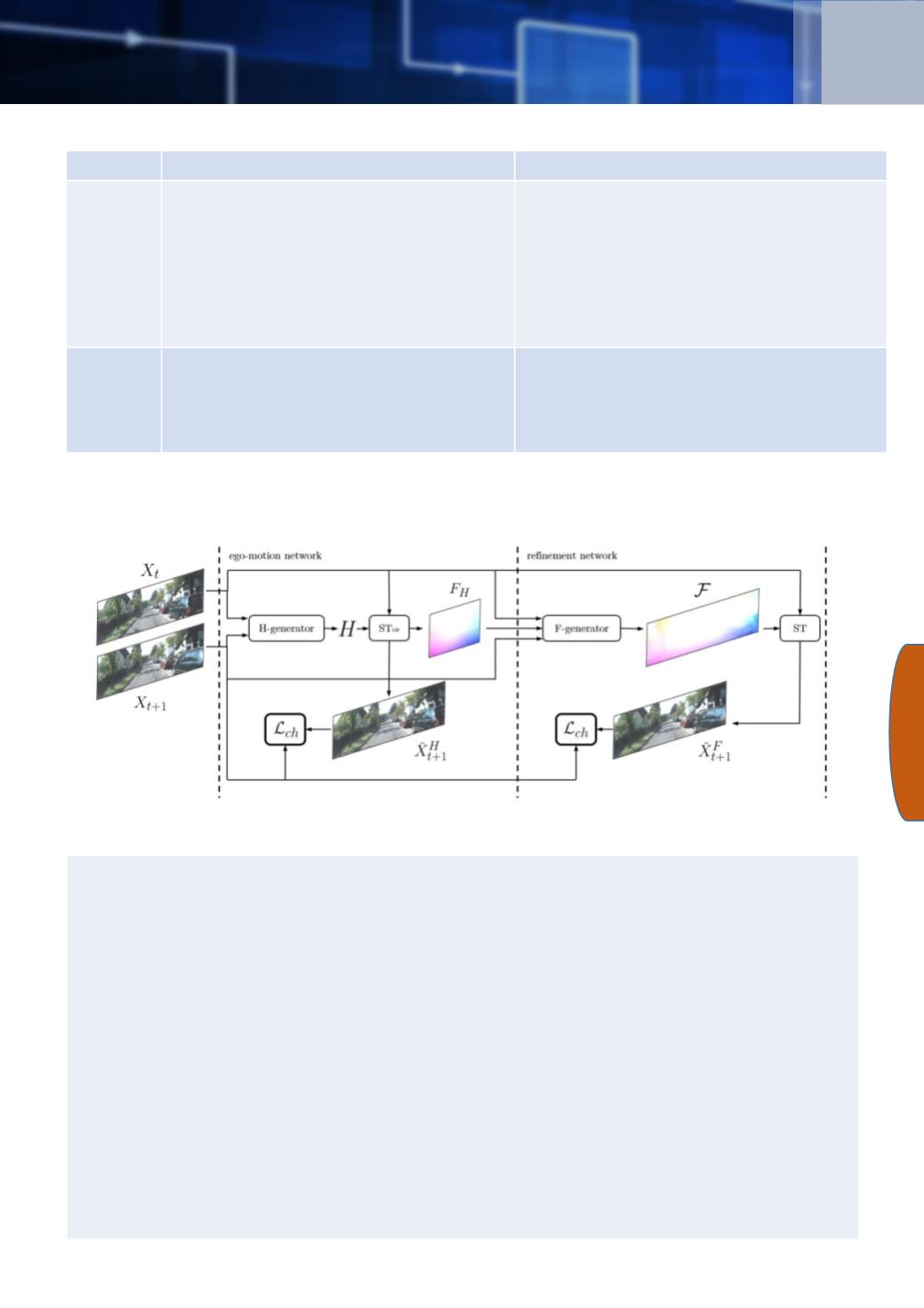
The architecture of the method is illustrated in the following figure:
Computer Vision NewsResearch
5
Research
Training
Testing
Input
A pair of successive input frames
denoted by
and
+1
Input frame
1. H-generator transform
2. ST network weights
3. F-generator network weights
Output 1. Homography transform
2. ST network weights
3. F-generator network weights
Estimate frame
+1
TransFlow consists of three main steps: (1) ego motion estimation; (2) motion
refinement; and (3) edge aware smoothing:
1. Ego-motion estimation is a global flow step approximating the motion of the car. It
consists of two parts:
a. H-generator network produces a dense global flow of the overall motion
b. ST - spatial transformer layer warps-in on main content.
2.
Motion refinement - produces a fine-grained flow. It also consists of two parts:
a. F-generator deeper network (structured similar to FlowNet) produces dense
pixel-level transformation.
b. ST - spatial transformer layer warps-in on main content.
3. Edge aware smoothing - aims at uniform flows within object boundaries.