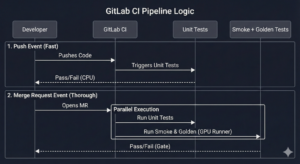
Part 4: Validation + Test
Making Your Metric Trustworthy (and Your Test Set Worth Something)
At some point, your model gets “good enough” that progress becomes harder to measure. This is where many teams fall into metric noise. They reshuffle validation too often, add cases randomly, and unknowingly turn their validation set into a moving target.
The result:
- Metrics drift
- Gains disappear
- Regressions go unnoticed
- Improvements become untrustworthy
Validation Should Be Piecewise Constant
Here’s the core idea:
Validation is a measurement instrument.
You don’t change your ruler every week.
So we enforce policy:
- Validation changes rarely
- When it changes, it changes deliberately
- Prefer adding cases rather than replacing
This reduces metric noise and gives you confidence that score changes reflect real progress.
Practical Policy
- Freeze validation set for a meaningful interval (weeks/months or N iterations)
- Save the validation file list in git
- Only update when there’s a clear reason:
- New device type appears
- New failure modes appear
- Distribution expands
When updating:
- Add cases (especially failure modes)
- Avoid rebuilding the full set
- Keep it representative — not only hard cases
The Test Set: Choose It Later Than You Think
Many teams create a test set too early. It feels “responsible.”
But in medical AI, early test sets often fail because:
- You don’t yet understand the distribution
- You don’t know failure modes
- You may accidentally make it too narrow
- You might tune to it over time
Instead, we lock the test set only after:
- Dozens of cases exist
- Variation is meaningful
- Failure modes are understood
- Pipeline is stable
What a Good Test Set Represents
Your test set should represent the world you’ll face later:
- Multiple devices
- Multiple sites
- Protocol variety
- Typical + hard cases
- Minimal annotation bias
And it should be treated as a final exam — not a weekly quiz.
Mistakes That Hurt Most Teams
- Skipping organize validation → problems show up later when debugging models
- Treating prepare as a basic script → silent failures and “model doesn’t learn”
- Constantly changing validation → you lose progress measurement
- Creating a test set too early → meaningless test or accidental tuning
- Not versioning datasets as products → impossible reproducibility
Final Thoughts: Make the Pipeline Boring So the Model Can Be Interesting
Medical AI needs stable measurement. The dataset pipeline is what makes that possible. It’s not glamorous — it’s systematic.
But if you invest in:
- Adapters per dataset
- Uniform output specs
- Layered validation
- Visual sanity checks
- Piecewise constant validation
- Delayed test-set locking
Then model iteration becomes faster, clearer, and more trustworthy.
And most importantly:
When your score improves, you can believe it.