Phenotyping
Phenotyping, in general, is a process by which different traits of a plant, such as nitrogen consumption, yield, and dimensions, are assessed. Knowledge regarding these traits and the way by which they are affected by different factors are key to agricultural progress. For its importance, phenotyping has been performed by farmers for hundreds of generations.
Until recent years, phenotyping strictly relied on manual measurements and “farmer intuition”. Nowadays, technological advances enable automatic, precise, high-throughput measurements as well as an exact analysis of the traits and factors that affect them, opening the door to a new age in agriculture.
As phenotyping largely relies on visible traits, advanced computer vision algorithms – such as those developed by RSIP Vision – play a key role in this field. Since plants are in many cases grown in an uncontrolled environment, yet precision agriculture requires, by its nature, precise measurements, phenotyping projects are best approached by a combination of algorithm types, to provide both precision and robustness.
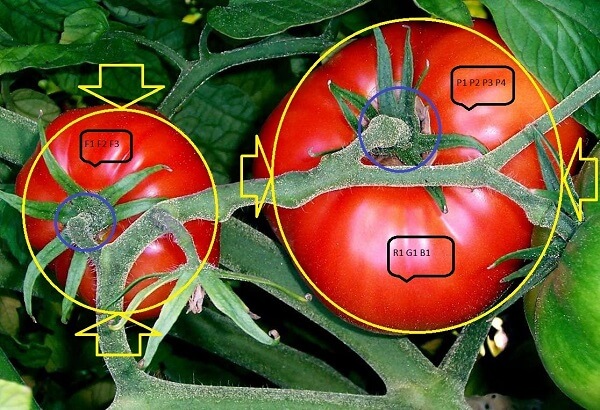
A request for such a project was brought forward by a client, regarding an automated system for phenotyping pepper and tomato plants in greenhouses. A single instance of the system consists of at least one camera, directed at 1-3 plants that are to be automatically analyzed. The main features of interest include the plant’s height and width along regions, color-based analysis and automatic fruit-yield estimation.
As in most outdoor scenarios, the initial challenge involved detecting the plant of focus and differentiating it from environment and the rest of the plants. We aimed at a solution which would be able to provide robust and reliable results for the specific scenario at hand, yet could be generalized to other conditions and plant types.
Detection of the plant was established in three steps. The first step produces the general position of the plant and is performed based on color-index and structural ques in relatively low resolution, saving computational resources and power – an important limiting factor in such systems. In the next step, the plant is detected in a precise manner, using an iterative process in which short segments are concatenated, until an anomaly in texture or geometry is reached, marking a transition between the surrounding environment and the plant. The segmentation then undergoes further refinement, taking into account a-prior knowledge regarding the plant and the environment.
Next, the dimensions of the plant are extracted using different techniques, relying on several color indices and on textures. The measurements are then converted from pixel units to a meaningful unit of measure (e.g. cm). Such a conversion can be generated in two ways: i) an artificial reference object can be placed next to the plant, providing an anchor for computing the needed transformations in an accurate manner; or ii) sensors that allow depth estimation, such as stereo cameras, can be incorporated in the hardware of the system, eliminating the need for a reference object.
Once the plant is detected and its position is well estimated, additional algorithmic layers can be implemented: advanced machine learning schemes are “taught“ to recognize specific plant structures such as the fruit and flowers, and obtain measurements regarding their dimensions, color and yield.
All data, in addition to proxy meta data, is collected and stored, enabling further analysis and statistics.