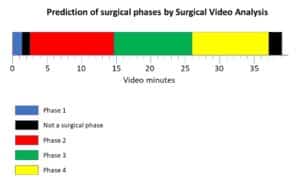
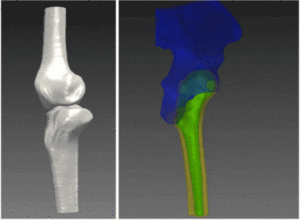
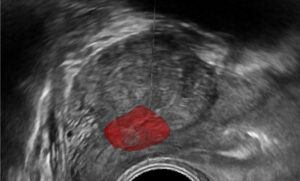
Deep Learning and Convolutional Neural Networks: RSIP Vision Blogs
In this page, you will learn about Computer Vision, Machine Vision and Image Processing. If you want to boost your project with the newest advancements of these powerful technologies, request a call from one of our best experts.
Deep Learning, what is it?
Briefly, deep learning is:
- A host of statistical machine learning techniques
- Enables the automatic learning of feature hierarchies
- Usually based on artificial neural networks
That is the gist. For something that appears to be fairly straightforward, there’s a lot of hype in the news about what has been achieved and what might be done with deep learning techniques in the future. Let’s start with an example of what has already been achieved to show why it has been garnering so much attention.
How is it Different?
In an interview after the competition, the winners of the competition emphasized the importance of feature generation, also called feature engineering. It is well-known that data scientists spend most of their time, effort, and creativity on engineering good features. On the other hand, they spend relatively little time running the actual machine learning algorithms. A toy example of an engineered feature would involve multiplying two columns and including this new resulting column as an additional descriptor (feature) of your data. In the case of the whales, the winning team transformed each sound to its spectrogram form and built features that describe how well the spectrogram matched some example templates (template matching). Next, they iterated new features that would help them correctly classify examples that they got wrong through the use of a previous set of features. As you can imagine, this process takes time, effort and considerable expertise.
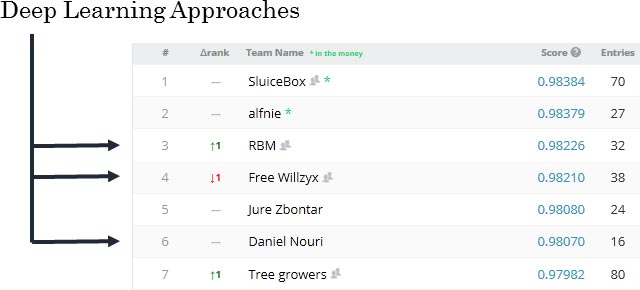
This novel approach of foregoing manual feature engineering, was also echoed in a Competitive Kaggle Data Science panel. Top Kagglers asserted: “Try deep learning to do automatic feature engineering – automation is good [for industry]“, “The only way to stand out in data science competitions is to have better features” and finally “I use all: First GLM, RF, GBM, then try to beat them all with Deep Learning“.
Finally, in an interview with the winner of the Merck Kaggle Challenge, George Dahl (supervised by Geoffrey Hinton, see below) described their approach:
“…our goal was to demonstrate the power of our models, we did no feature engineering and only minimal preprocessing. The only preprocessing we did was occasionally, for some models, to log-transform each individual input feature/covariate. Whenever possible, we prefer to learn features rather than engineer them.”
As Dallin Akagi succinctly summarizes,
“The takeaway is that deep learning excels in tasks where the basic unit, a single pixel, a single frequency, or a single word/character has little meaning in and of itself, but a combination of such units has a useful meaning.”
Deep learning can learn such useful combinations of values without human intervention. The ubiquitous example used when discussing deep learning’s ability to learn features from data is the MNIST dataset of handwritten digits. When presented with tens of thousands of handwritten digits a deep neural network can learn that it is useful to look for loops and lines when trying to classify the digits.

What Garnered Renewed Attention for Neural Networks?
Neural networks gained tremendous popularity back in the 1980s, peaking in the early 1990s. Their use slowly declined after that. There was a lot of buzz and some high expectations, but in the end the neural network models did not live up to their potential. So, what was the problem? The answer lies in the ‘deep’ component of deep learning.
Standard neural networks are composed of layers of “neurons”. These layers are usually feed forward only and are trained by examples (for classification or regression). Primate brains do a similar thing in the visual cortex, so the hope was that using more layers in a neural network would allow it to learn better models. However, researchers found that training models with many layers doesn’t work. The general understanding came to be that only shallow networks (1-2 layers) can be trained successfully. The standard shallow neural network has only a single layer of data representation (see figure below). Learning in a deep neural network, one with more than one or two layers of data representation, appeared to be unfeasible. In reality, deep learning has been around for as long as neural networks have – we just couldn’t get it to work.
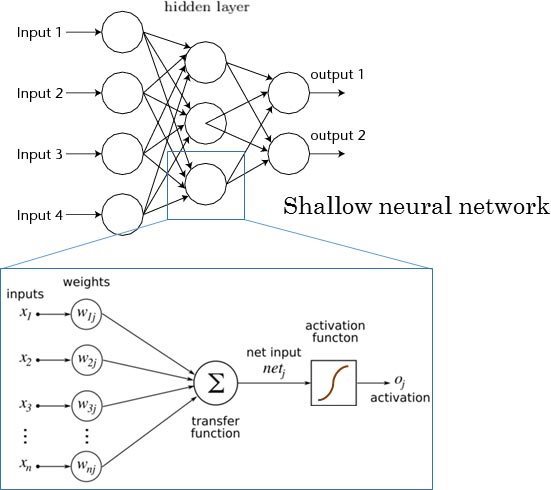
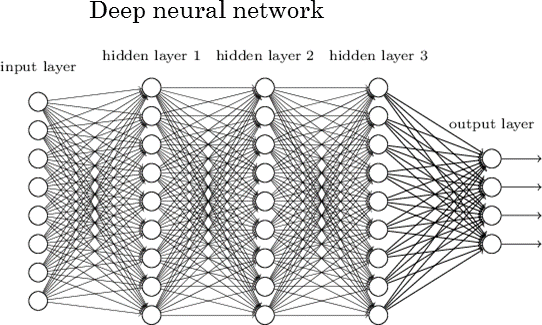
Deep neural networks have more than two hidden layers: simple.
The Breakthrough
So, how did they get deep neural networks to work? Before 2006, the earliest layers in a deep neural network simply were not able to learn useful representations of the data. In many cases they failed to learn anything at all. Instead the parameters of these layers stayed close to their random initializations. This was due to the nature of the training algorithm for neural networks. However, using different (and mostly novel) techniques, each of these three groups was able to get these early layers to learn useful representations. This resulted in much more powerful neural networks. A full description of their contributions is beyond the scope of this post. Briefly some of the things that made deep learning possible were: using a simple optimizer, namely stochastic gradient descent; using unsupervised data to pre-train models to automate feature extraction; improvements to the neural networks themselves (transfer functions and initialization); using larger and larger data sets; and finally using GPUs to accommodate the considerable computational costs incurred by deep neural network models combined with large datasets.
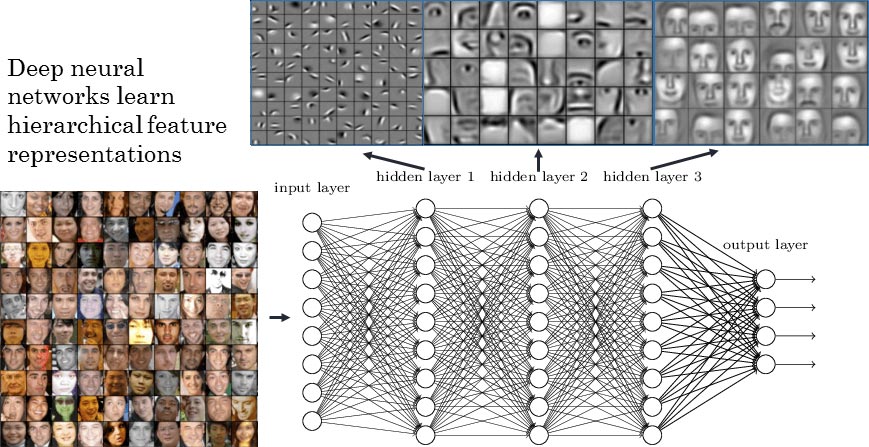
Now that the aforementioned problem has been circumvented, we ask, what is it that these neural networks learn? Let’s consider the above example, at the lowest level, the network fixates on patterns of local contrast as important. The following layer is then able to use those patterns of local contrast to fixate on things that resemble eyes, noses, and mouths. Finally, the top layer is able to apply those facial features to face templates. A deep neural network is capable of composing features of increasing complexity in each of its successive layers.
It is this automated learning of data representations and features that the hype is all about. Such an application of deep neural networks has seen models that successfully learn useful hierarchical representations of images, audio and written language. These learned feature hierarchies in these domains can be construed as:
Image recognition: Pixel → edge → texton → motif → part →object
Text: Character → word → word group → clause → sentence
Speech: Sample → spectral band → sound →…→ phone → phoneme → word
In summary, these breakthroughs have enabled deep neural networks that are able to automatically learn rich representations of data. This accomplishment has proven particularly useful in areas like computer vision, speech recognition, and natural language processing.
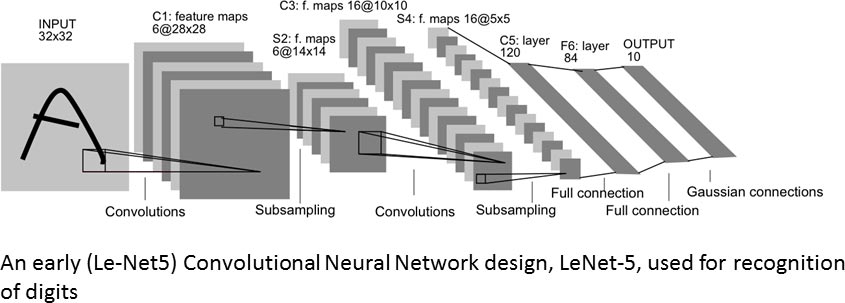
Convolutional Neural Networks